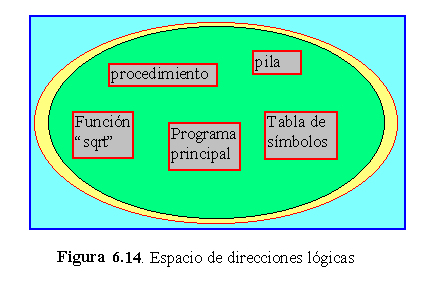
¿Cuál es la visión de la memoria que tiene el usuario ? Concibe el usuario la memoria como una tabla lineal de palabras, algunas de las cuales contienen instrucciones mientras que otras contienen datos, o bien se prefiere alguna otra visión de la memoria ? Hay un acuerdo general en que el usuario o programador de un sistema no piensa en la memoria como una tabla lineal de palabras. Más bien prefieren concebirla como una colección de segmentos de longitud variable, no necesariamente ordenados (fig. 6.14).
Consideremos cómo ve usted un programa cuando lo está escribiendo. Piensa en él como un programa principal, con un conjunto de subrutinas, procedimientos, funciones o módulos. También puede haber diversas estructuras de datos: tablas, matrices, pilas, variables, etc. Cada uno de estos módulos o elementos de datos se referencian por un nombre. Usted habla de la "tabla de símbolos", A "la función Sqrt", "el programa principal", sin tener en cuenta qué direcciones de memoria ocupan estos elementos. Usted no se preocupa de si la tabla de símbolos se almacena antes o después de la función Sqrt. Cada uno de estos elementos es de longitud variable; la longitud está definida intrínsecamente por el propósito del segmento en el programa. Los elementos dentro de un segmento están identificados por su desplazamiento desde el principio del segmento: la primera instrucción del programa, la decimoséptima entrada de la tabla de símbolos la quinta función Sqrt, etc.
La segmentación es un esquema de administración de la memoria que soporta la visión que el usuario tiene de la misma. Un espacio de direcciones lógicas es una colección de segmentos. Cada segmento tiene un nombre y una longitud. Las direcciones especifican tanto el nombre del segmento como el desplazamiento dentro del segmento. Por lo tanto, el usuario especifica cada dirección mediante dos cantidades: un nombre de segmento y un desplazamiento. (Compárese este esquema con la paginación, donde el usuario especificaba solamente una única dirección, que el hardware particionaba en número de página y desplazamiento, siendo todo ello invisible al programador).
Por simplicidad de implementación, los segmentos están numerados y se referencian por un número de segmento en lugar de por un nombre. Normalmente el programa de usuario se ensambla (o compila), y el ensamblador (o el compilador) construye automáticamente segmentos que reflejan el programa de entrada. Un compilador de Pascal podría crear segmentos separados para (1) las variables globales, (2) la pila de llamada de procedimientos, para almacenar parámetros y devolver direcciones, (3) el código de cada procedimiento o función, y (4) las variables locales de cada procedimiento y función. El cargador tomaría todos esos segmentos y les asignaría números de segmento.
